LLM知识汇总
数据格式
浮点数
fp32, 即常用的single precision floating point number,一个符号位,8个指数位,23个尾数位。 fp16, 即half precision floating point number, 简称half float,一个符号位,5个指数位,10个尾数位。 fp16的主要问题是指数位不够,从8降到5,表达的数值范围不够了。从1e-127~1e+128,降到了1e-15~1e+16. tf32,即tensor float 32,由nVidia提出,一个符号位,8个指数位,10个尾数位。指数位个数与fp32相同,表达的数值范围相同。尾数减少了,精度不如fp32,但与fp16是一样的。共使用19个比特。 bf16,即brain float 16,由Google Brain团队提出,一个符号位,8个指数位,7个尾数位。指数位个数与fp32相同,表达的数值范围相同,尾数更少了,精度更差了,不如fp16,但AI计算能容忍。共使用16比特。
模型结构
基本结构
归一化
LayerNorm
定义
Layer Normalization(层归一化)是一种常用的归一化方法,其计算公式如下:
对于一个形状为$(N, D)$的输入张量$x$,其中$N$是批量大小,$D$是特征维度。
首先,计算每个样本在特征维度上的均值$\mu$和方差$\sigma^{2}$:
- $\mu=\frac{1}{D}\sum_{i = 1}^{D}x_{i}$
- $\sigma^{2}=\frac{1}{D}\sum_{i = 1}^{D}(x_{i}-\mu)^{2}$
然后,对输入进行归一化:
- $\hat{x}=\frac{x_{i}-\mu}{\sqrt{\sigma^{2}+\epsilon}}$
其中,$\epsilon$是一个很小的常数,通常取$1e - 5$或$1e - 8$,用于防止分母为零。
最后,通过可学习的参数$\gamma$和$\beta$对归一化后的结果进行缩放和平移:
- $y=\gamma\hat{x}+\beta$
$\gamma$和$\beta$是可学习的参数,通过训练来调整,以使得模型能够更好地学习数据的特征。
BatchNorm对比
层归一化(Layer Normalization)和批量归一化(Batch Normalization)有以下区别:
归一化对象
- Batch Normalization:对一个批次的数据在特征维度上进行归一化,即对不同样本的同一特征进行归一化。
- Layer Normalization:对单个样本在所有特征维度上进行归一化,是在一个样本的内部对其所有特征进行操作。
计算方式
- Batch Normalization:计算一个批次数据的均值和方差,然后对该批次内的所有样本进行归一化。
- Layer Normalization:独立计算每个样本的均值和方差,然后对该样本进行归一化。
应用场景
- Batch Normalization:适用于计算机视觉等领域,在处理图像数据时,能够有效加速模型收敛,减少梯度消失和爆炸问题。
- Layer Normalization:在自然语言处理中表现较好,对于变长序列数据,能够更好地适应不同长度的输入,对每个样本独立归一化,不受批次中其他样本的影响。
对模型训练的影响
- Batch Normalization:由于依赖批次统计信息,在训练和推理时的行为有所不同,可能需要进行一些额外的处理来保证模型的稳定性。
- Layer Normalization:在训练和推理时的行为一致,因为它只依赖于单个样本的统计信息,不需要进行特殊的处理来适应不同的阶段。
超参数敏感性
- Batch Normalization:对批次大小较为敏感,批次大小的变化可能会影响归一化的效果和模型的性能。
- Layer Normalization:对批次大小不敏感,更适合于批次大小较小或者动态变化的情况。
与RMS Norm对比
RMS Norm(Root Mean Square Normalization)即均方根归一化,是一种归一化方法,与Layer Norm和Batch Norm有相似之处,但也有不同。以下是其相关介绍:
计算公式 对输入张量$x$,其计算公式为$y=\frac{x}{\sqrt{E[x^{2}]+\epsilon}}$,其中$E[x^{2}]$是$x$元素平方的均值,$\epsilon$是一个小常数,防止分母为零。
与其他归一化方法的区别
- 计算方式:Layer Norm计算均值和方差时是在特征维度上对所有元素进行操作,Batch Norm是在一个批次内对不同样本的同一特征进行计算,而RMS Norm主要关注元素平方的均值,计算相对更简单,不涉及减去均值的操作。
- 对数据的影响:Layer Norm和Batch Norm会将数据归一化到均值为0、方差为1的分布,而RMS Norm主要是对数据的尺度进行调整,使其元素的均方根值处于一定范围,不一定改变数据的均值。
- 应用场景:RMS Norm在一些自然语言处理任务,如Transformer架构中有所应用,能在一定程度上提高模型的稳定性和泛化能力。与Layer Norm类似,它也适用于处理序列数据,但在一些具体任务中的表现可能与Layer Norm有所不同,具体使用哪种需要根据实际情况进行实验和选择。
使用场景
Pre-input Layer Normalization: (1)缓解输入数据波动较大的情况,(2)输入数据分布在重要信息也会被平滑掉一些。 Post-output Layer Normalization:稳定输出,对模型能力影响不大,主要是对分类、回归任务进行前处理。 Inter-Layer Normalization:(1)稳定数据,防止梯度爆炸或消失,(2)提高模型泛化能力,(3)计算开销大。
各模型应用情况:
- GPT 在Attention和FFN之间使用Layer Norm
- BERT 在每一层的输入输出使用Layer Norm
- LLama在Attention和FFN之间使用RMS Norm
- 千问2, post_attetion, input使用RMS Norm
- Whisper使用attention_ln, mlp_ln, ln_post(最后一层的后面)
- Gemma,有input_layernorm, post_attention, pre_ffn, post_ffn,都是RMS Norm。
- minicpm,在q, kv分别使用layer norm, attenttion, 和input。都是RMS Norm。
激活函数
常用激活函数列表
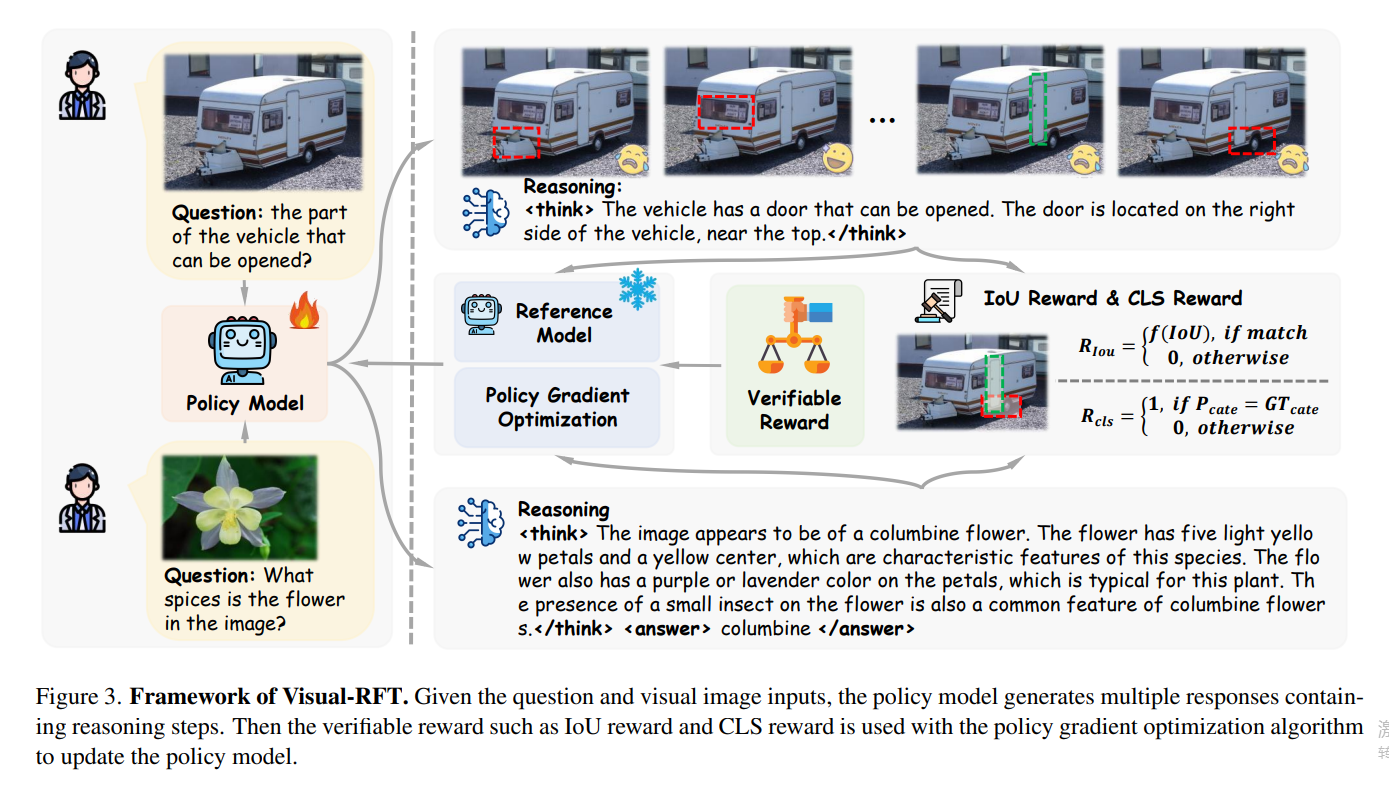
在语言模型(LM)和大型语言模型(LLM)中,常用的激活函数有以下几种:
-
ReLU(Rectified Linear Unit)
- 公式:$f(x)=\max(0,x)$。
- 特点:计算简单高效,能有效缓解梯度消失问题,加快模型收敛速度。在处理自然语言中的稀疏数据时表现良好,能使模型自动学习哪些特征是重要的,将不重要的特征置为0,起到特征选择的作用。但它在输入小于0时梯度为0,可能导致部分神经元在训练过程中"死亡",即不再被激活。
- 应用:广泛应用于各种LLM的神经网络架构中,如Transformer的前馈神经网络部分。
-
GELU(Gaussian Error Linear Unit)
- 公式:$GELU(x)=x\Phi(x)$,其中$\Phi(x)$是标准正态分布的累积分布函数。
- 特点:它是一种平滑的非线性激活函数,比ReLU更加柔和。GELU考虑了输入的整体分布情况,能根据输入的概率分布来调整输出,具有更好的正则化效果,有助于提高模型的泛化能力。
- 应用:在许多现代LLM中被广泛使用,如BERT、GPT - 3等都采用了GELU激活函数,以提高模型的性能和稳定性。
-
Swish(也叫SiLU)
- 公式:$Swish(x)=x\times\sigma(x)$,其中$sigma(x)$是Sigmoid函数。
- 特点:Swish是一种自门控激活函数,它结合了Sigmoid函数的门控机制和线性函数的特性。具有平滑、非单调的特性,在不同的输入范围内表现出不同的行为,能够更好地适应复杂的语言数据分布。同时,它在训练过程中能够保持较好的梯度流,有助于模型的收敛。
- 应用:在一些LLM的研究和实践中也有应用,例如在一些对模型性能有较高要求的自然语言处理任务中,Swish激活函数能够帮助模型更好地学习语言的复杂模式。
-
Softmax
- 公式:$Softmax(x_i)=\frac{e^{x_i}}{\sum_{j=1}^{n}e^{x_j}}$,用于将一个数值向量转换为表示各个类别概率的概率分布向量。
- 特点:它将输入值转换为0到1之间的概率值,且所有概率值之和为1,能够很好地表示分类任务中各个类别的可能性。
-
应用:通常用于LLM的输出层,将模型的输出转换为各个可能词汇或标签的概率分布,以便进行分类或生成任务。例如,在语言生成任务中,通过Softmax函数可以得到下一个单词的概率分布,从而根据概率采样或选择概率最高的单词作为生成结果。
从图中可以看出,GELU和SiLU(Swish)差不多,但是GELU计算量会小一些。
各模型应用情况
以下是这些模型常用的激活函数:
- Qwen2、Llama3:在MLP中使用SiLU。
- Gemma2:PytorchGELUTanh
Attention
MHA
多头与不多头不同之处在于,每个k*q都会产生一个seq_len * seq_len的矩阵。如果没有多头的话,只有一个seq_len * seq_len的矩阵。
@startuml
skinparam sequence {
ArrowColor #0079BF
LifeLineBorderColor #0079BF
LifeLineBackgroundColor #E0F2FF
ParticipantBorderColor #0079BF
ParticipantBackgroundColor #E0F2FF
ArrowThickness 2
}
skinparam backgroundColor #F5F5F5
skinparam title "多头注意力机制(Multi-Head Attention)流程图"
actor "输入序列 (Query, Key, Value)" as input_seq
rectangle "线性变换层" as linear_layer {
component "Query 线性变换" as query_linear
component "Key 线性变换" as key_linear
component "Value 线性变换" as value_linear
}
rectangle "多头拆分" as split_heads {
component "拆分 Query" as split_query
component "拆分 Key" as split_key
component "拆分 Value" as split_value
}
rectangle "注意力计算" as attention_calculation {
component "计算 Query 和 Key 的点积" as dot_product
component "缩放操作" as scale
component "Softmax 归一化" as softmax_op
component "与 Value 相乘并求和" as multiply_sum
}
rectangle "多头合并" as merge_heads {
component "合并多头结果" as merge_result
}
rectangle "最终线性变换" as final_linear_layer {
component "最终线性变换" as final_linear
}
actor "输出序列" as output_seq
input_seq --> query_linear : Query
input_seq --> key_linear : Key
input_seq --> value_linear : Value
query_linear --> split_query : 变换后的 Query
key_linear --> split_key : 变换后的 Key
value_linear --> split_value : 变换后的 Value
split_query --> dot_product : 多头 Query
split_key --> dot_product : 多头 Key
dot_product --> scale : 点积结果
scale --> softmax_op : 缩放后的分数
softmax_op --> multiply_sum : 归一化分数
split_value --> multiply_sum : 多头 Value
multiply_sum --> merge_result : 多头加权结果
merge_result --> final_linear : 合并后的结果
final_linear --> output_seq : 输出
@enduml
拆分过程:
@startuml
skinparam sequence {
ArrowColor #0079BF
LifeLineBorderColor #0079BF
LifeLineBackgroundColor #E0F2FF
ParticipantBorderColor #0079BF
ParticipantBackgroundColor #E0F2FF
ArrowThickness 2
}
skinparam backgroundColor #F5F5F5
skinparam title "多头注意力机制中拆分与合并过程 (dim=4096, heads=8)"
actor "线性变换后的 Query [batch_size, seq_length, 4096]" as query_transformed
actor "线性变换后的 Key [batch_size, seq_length, 4096]" as key_transformed
actor "线性变换后的 Value [batch_size, seq_length, 4096]" as value_transformed
rectangle "拆分操作" as split_operation {
component "拆分 Query 为 8 个头" as split_query
component "拆分 Key 为 8 个头" as split_key
component "拆分 Value 为 8 个头" as split_value
}
actor "8 个头的 Query [batch_size, seq_length, 8, 512]" as multi_head_query
actor "8 个头的 Key [batch_size, seq_length, 8, 512]" as multi_head_key
actor "8 个头的 Value [batch_size, seq_length, 8, 512]" as multi_head_value
rectangle "注意力计算" as attention_calculation {
component "每个头计算注意力" as attn_calc
}
actor "8 个头的输出 [batch_size, seq_length, 8, 512]" as multi_head_output
rectangle "合并操作" as merge_operation {
component "合并 8 个头的输出" as merge_output
}
actor "合并后的输出 [batch_size, seq_length, 4096]" as final_output
query_transformed --> split_query : 线性变换后的 Query
split_query --> multi_head_query : 8 个头的 Query
key_transformed --> split_key : 线性变换后的 Key
split_key --> multi_head_key : 8 个头的 Key
value_transformed --> split_value : 线性变换后的 Value
split_value --> multi_head_value : 8 个头的 Value
multi_head_query --> attn_calc : 8 个头的 Query
multi_head_key --> attn_calc : 8 个头的 Key
multi_head_value --> attn_calc : 8 个头的 Value
attn_calc --> multi_head_output : 8 个头的输出
multi_head_output --> merge_output : 8 个头的输出
merge_output --> final_output : 合并后的输出
@enduml
MQA
GQA
MLA
FFN
在Transformer架构里,前馈神经网络(FFN)有时会采用门控机制,像GLU(Gated Linear Unit)这种形式,此时会涉及到gate、up、down矩阵。接下来我会详细说明计算过程,并且借助mermaid为你绘制计算流程示意图。
计算过程
假设输入为向量 (x),其维度是 (d_{model})。FFN里的门控机制一般包含以下计算步骤:
-
线性变换:对输入 (x) 分别做三次线性变换,得到
gate、up、down矩阵的中间结果。这里会用到三个不同的权重矩阵 (W_{gate})、(W_{up}) 和 (W_{down}),以及对应的偏置向量 (b_{gate})、(b_{up}) 和 (b_{down})。- (gate = \text{Linear}{gate}(x)=W{gate}x + b_{gate})
- (up = \text{Linear}{up}(x)=W{up}x + b_{up})
- (down = \text{Linear}{down}(x)=W{down}x + b_{down})
-
门控操作:使用激活函数(例如Sigmoid)对
gate进行处理,然后和up逐元素相乘,这一过程起到了门控的作用,能够控制信息的流通。- (gated = \sigma(gate)\odot up) 其中,(\sigma) 代表激活函数,(\odot) 表示逐元素相乘。
-
最终输出:把门控操作的结果和
down相加,就得到了FFN的最终输出 (y)。- (y = \text{ReLU}(gated + down))
示意图
此图展示了带有门控机制的FFN的计算流程:
- 输入 (x) 经过线性变换得到
gate、up、down。 -
gate经过Sigmoid激活后和up逐元素相乘,得到gated。 -
gated和down相加,再经过ReLU激活,最终得到输出 (y)。 ```plantuml @startuml skinparam monochrome true skinparam backgroundColor #EEEEEE skinparam sequence { ArrowColor DeepSkyBlue LifeLineBorderColor DeepSkyBlue LifeLineBackgroundColor #A9DCDF ParticipantBorderColor DeepSkyBlue ParticipantBackgroundColor #E5F6FF }
actor "输入 x" as input rectangle "线性变换" as linear { component "gate = W_gate * x + b_gate" as gate component "up = W_up * x + b_up" as up component "down = W_down * x + b_down" as down } rectangle "门控操作" as gate_op { component "Sigmoid激活" as sigmoid component "逐元素相乘" as mul component "gated = σ(gate) ⊙ up" as gated } rectangle "最终输出" as final { component "相加" as add component "ReLU激活" as relu component "输出 y" as output }
input –> gate : 线性变换 input –> up : 线性变换 input –> down : 线性变换 gate –> sigmoid : Sigmoid激活 sigmoid –> mul : σ(gate) up –> mul : up mul –> gated : gated gated –> add : gated down –> add : down add –> relu : gated + down relu –> output : ReLU激活
@enduml ```
MoE
LoRA
模型训练
Llama
The Llama 3 Herd of Models
pretrainin
post-training
RL
SFT
DPO
Apple Intelligence Foundation Models
https://machinelearning.apple.com/research/introducing-apple-foundation-models
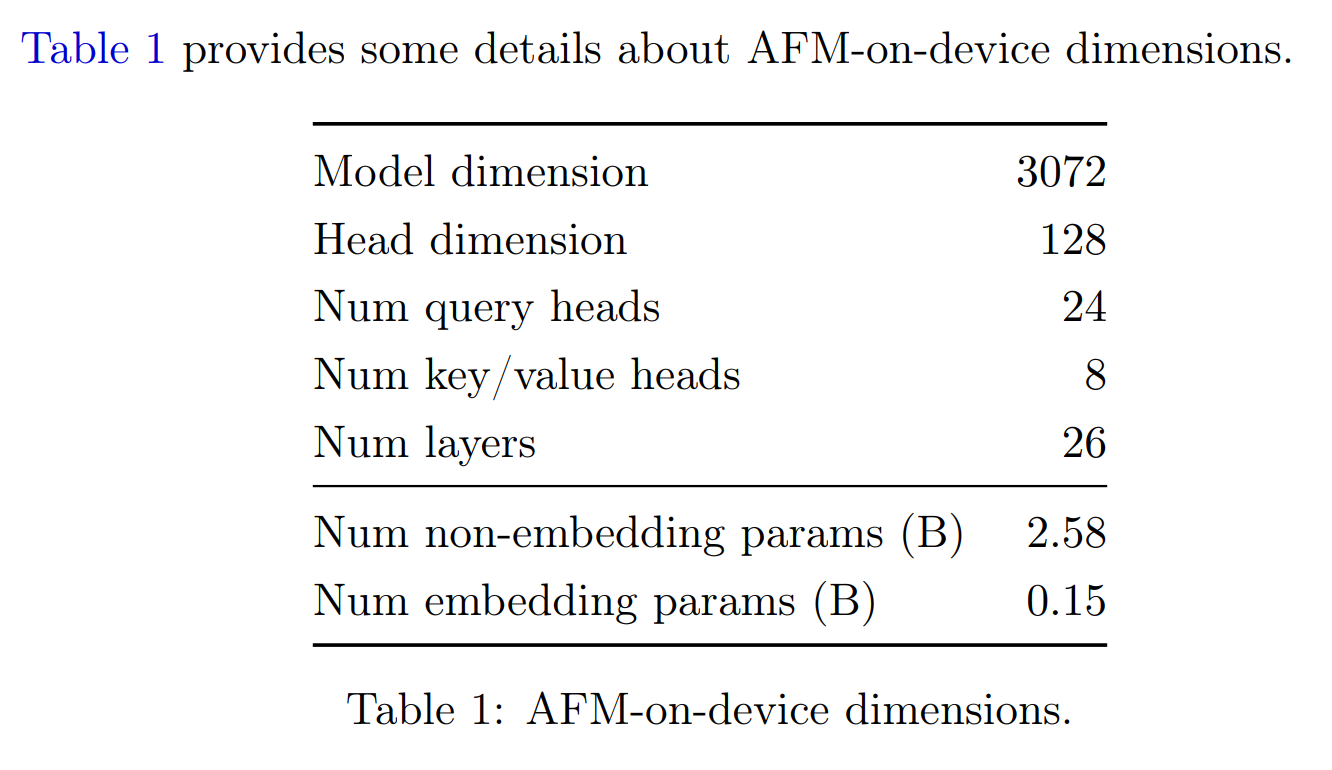 AFM-on-device模型参数量2.58B(0.15B embedding),推理速度是
AFM-on-device模型参数量2.58B(0.15B embedding),推理速度是0.6 ms per prompt token,30 token/s without token speculation。
优化点:
- Shared input/output embedding
- GQA: 24 query, 8 kv heads
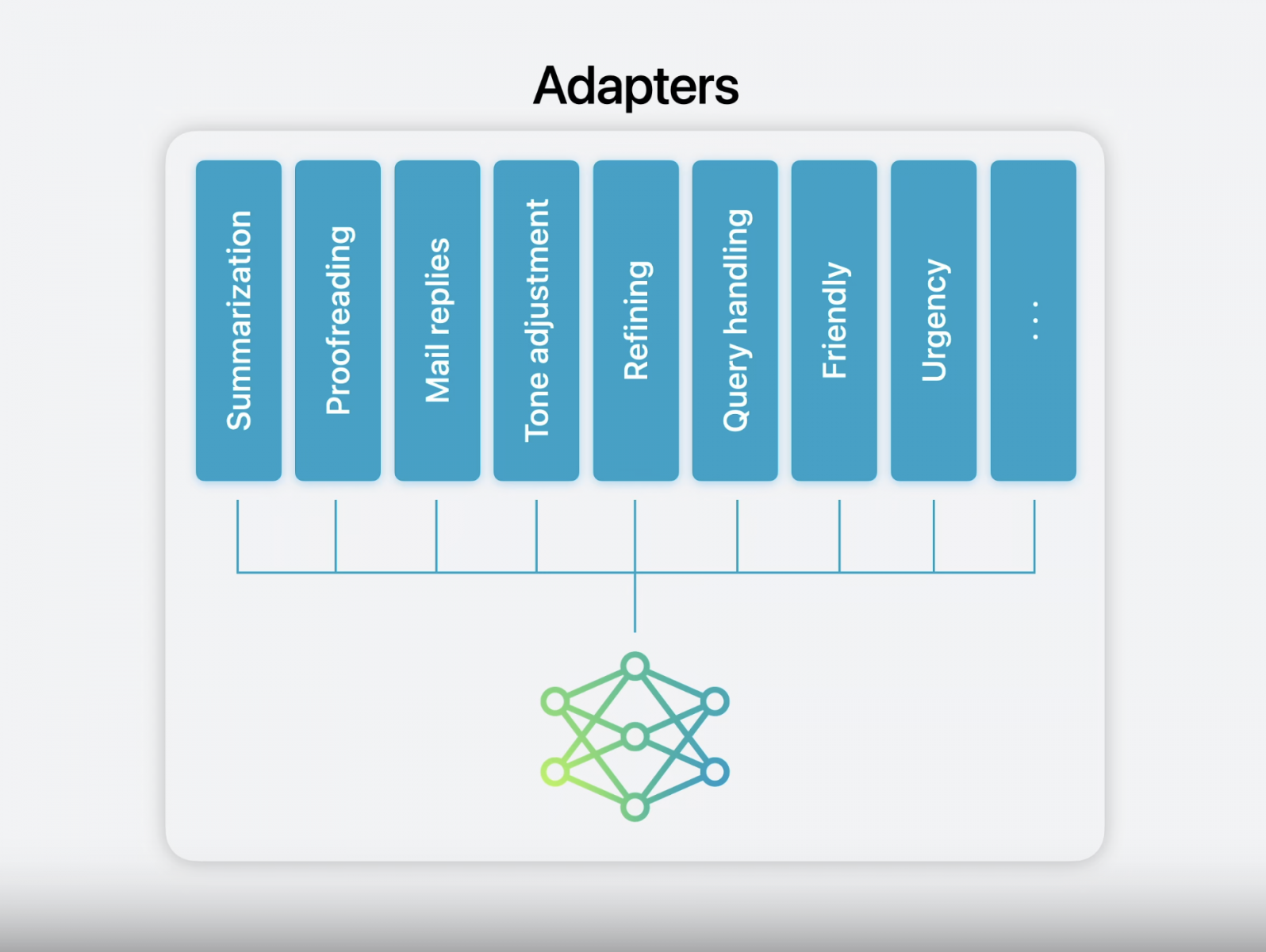
- LoRA adpater on-the-fly,rank 16的adapter大小在10MB量级。
- 量化:4比特、2比特混合量化,总体小于4bits, 3.7bpw。GPTQ、AWQ。
- Accuracy recovery adapter
Device model用于:
- 便签中写作、校对、总结等场景。
- 邮件、短信、通知的优先级+紧急程度判断
- 邮件总结、回复、语气调整
DeepSeek
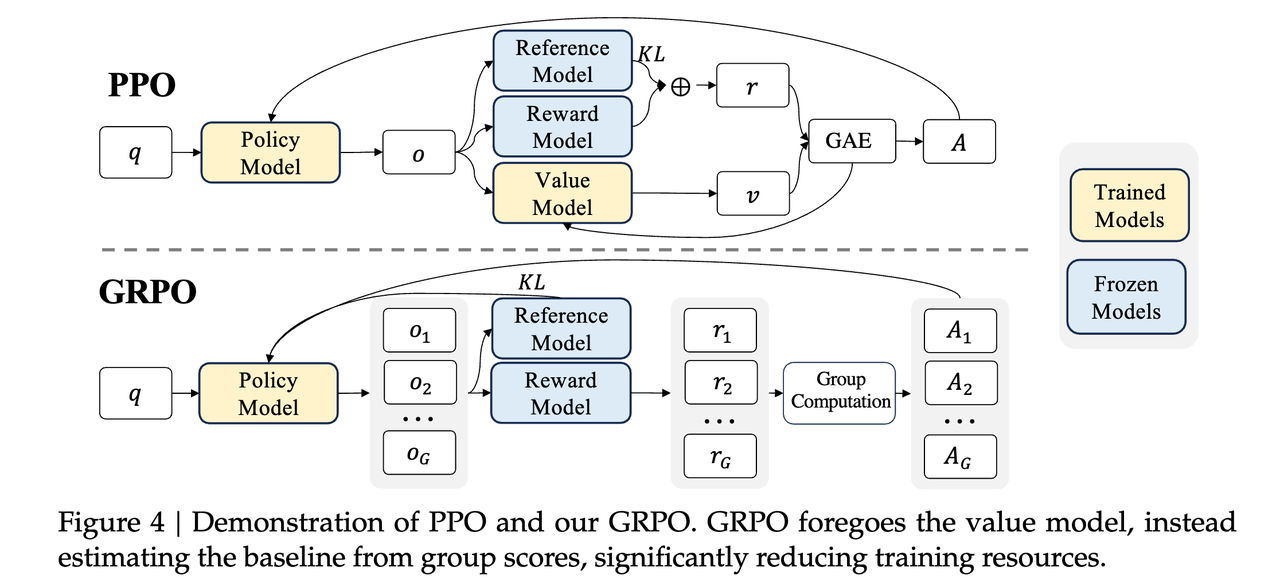
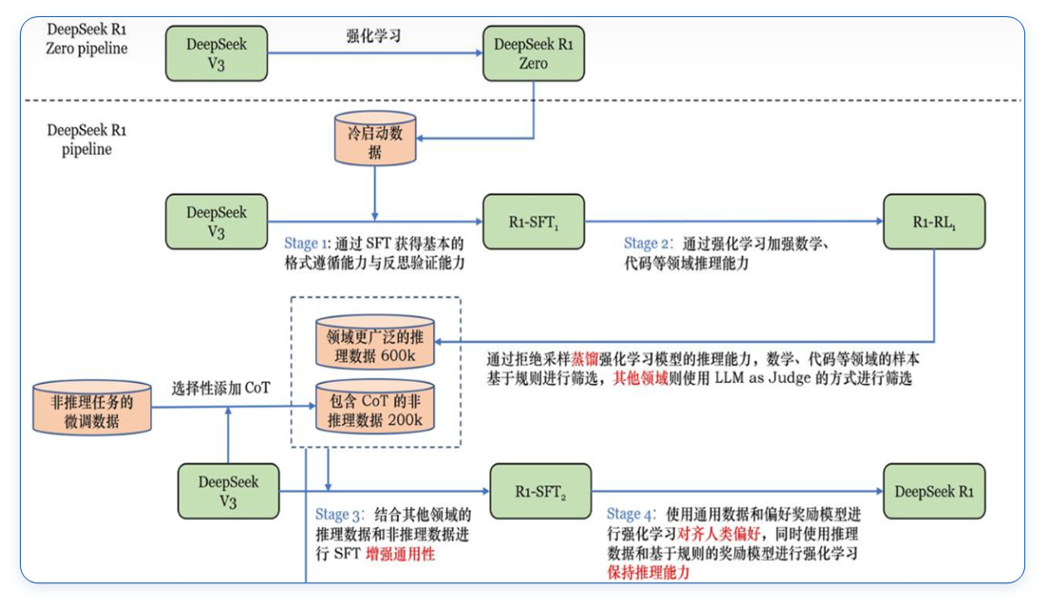
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
https://arxiv.org/abs/2501.12948
论文要求:
- 只使用RL来强化自身能力,这是self-evolution,不需要人类给正确答案。少量cold start 数据(几千条)有帮助。
- 大的模型能过RL学习到的知识,小的模型(32B)无法通过RL学到,所以蒸馏更有用。
https://arxiv.org/abs/2402.03300