C++ 全新体验:彩色Hello World
新增C++11支持(推荐用C++17以上编译)
话不多说,先看看效果
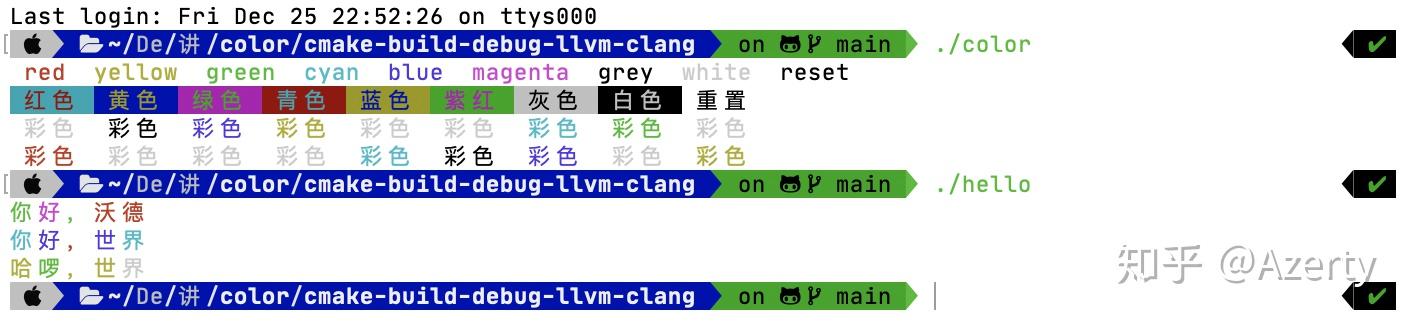
项目已经发布到GitHub上,
Wongboo/color_ostreamgithub.com/Wongboo/color_ostream/tree/main
借鉴了colored-cout,不过有较大区别。
项目是header-only(仅头文件)的,直接include就能用。编译时最好确认文件格式是UTF-8带BOM的。
项目的实现这里先挖个坑(实现还有点坑,大家可以给点更好的建议),我们先来看看,这个头文件的使用是多么方便吧,只需要改动流输出符号的名字:
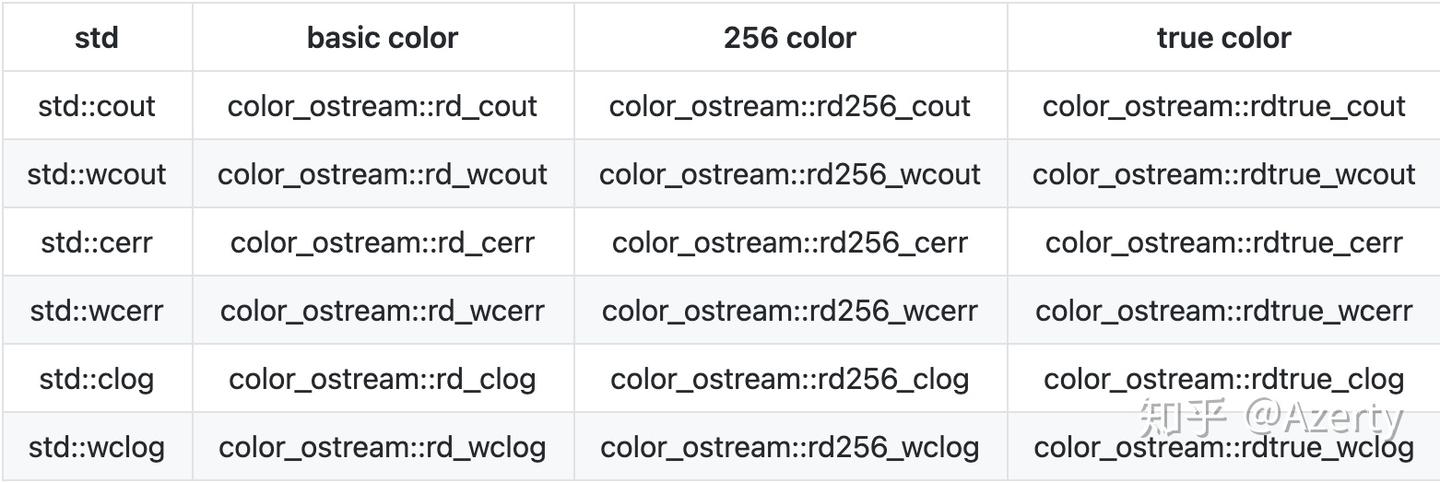
转化
注意:256 color和true color的支持需要相应的terminal支持,如Windows terminal, Visual studio调试控制台,MacOS下的terminal.app,iterm2均支持256 color
hello.cpp:
//hello.cpp
int main() {
rd_wcout.imbue(std::locale(std::locale(),"",LC_CTYPE));
rd_wcout << L"你好,沃德\n";
rd_wcout << L"你好,世界\n";
rd_wcout << L"哈啰,世界\n";
rd256_wcout << L"\n256 color" << std::endl;
rd256_wcout << L"你好,沃德\n";
rd256_wcout << L"你好,世界\n";
rd256_wcout << L"哈啰,世界\n";
rdtrue_wcout << L"\ntrue color" << std::endl;
rdtrue_wcout << L"你好,沃德\n";
rdtrue_wcout << L"你好,世界\n";
rdtrue_wcout << L"哈啰,世界\n";
return 0;
}
color.cpp:
//color.cpp
#include "color_ostream.h"
using namespace color_ostream;
using namespace std;
int main([[maybe_unused]] int argc, [[maybe_unused]] char *argv[]) {
cout << clr::red << " red "
<< clr::yellow << " yellow "
<< clr::green << " green "
<< clr::cyan << " cyan "
<< clr::blue << " blue "
<< clr::magenta << " magenta "
<< clr::grey << " grey "
<< clr::white << " white "
<< clr::reset << " reset\n";
wcout.imbue(locale(locale(),"",LC_CTYPE));
wcout << clr::red << clr::on_cyan << L" 红色 "
<< clr::yellow << clr::on_blue << L" 黄色 "
<< clr::green << clr::on_magenta << L" 绿色 "
<< clr::cyan << clr::on_red << L" 青色 "
<< clr::blue << clr::on_yellow << L" 蓝色 "
<< clr::magenta << clr::on_green << L" 紫红 "
<< clr::grey << clr::on_white << L" 灰色 "
<< clr::white << clr::on_grey << L" 白色 "
<< clr::reset << L" 重置\n";
for (size_t i{}; i < 9; ++i)
wcout << random_color << L" 彩色 ";
wcout << '\n';
random_generator rd;
for (size_t i{}; i < 9; ++i)
wcout << clrs[random_color.get_num()] << L" 彩色 ";
wcout << '\n';
}
项目的实现还请大家多给一些建议,感觉还有好些可改进的地方,
C/C++ 编程有哪些值得推荐的工具
作者:程序喵大人
链接:https://www.zhihu.com/question/23357089/answer/1992218543
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
本人只会Linux平台C++开发,介绍下自己常用的C++相关工具:
- IDE:VSCode(画图会使用VSCode里的drawio插件)、Clion(付费,但是这钱花的也值)、XCode(苹果平台的)、emacs。
- 代码调试工具:gdb、lldb、valgrind。
- 构建系统:CMake、Bazel、Ninja。
- 静态代码检测工具:cppcheck、Clang-Tidy、PC-lint、SonarQube+sonar-cxx、Facebook的infer、Clang Static Analyzer。
- 内存泄漏检测工具:valgrind、ASan、mtrace、ccmalloc、debug_new。
- profiling工具:gperftools、perf、intel VTune、AMD CodeAnalyst、gnu prof、Quantify。
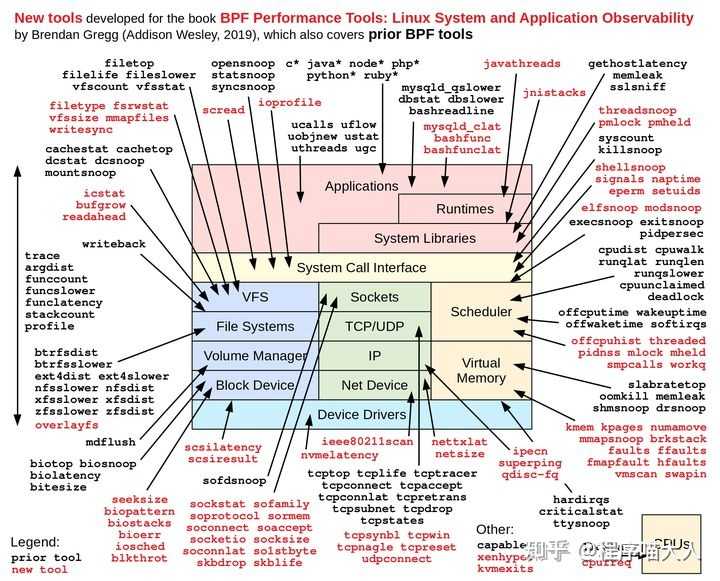
关于性能方面的工具完全可以看这个网站:
http://www.brendangregg.com/linuxperf.htmlwww.brendangregg.com/linuxperf.html
里面很多相当有用的图片,比如:
- 网络I/O:dstat、tcpdump(推荐)、sar
- 磁盘I/O:iostat(推荐)、dstat、sar
- 文件系统空间:df
- 内存容量:free、vmstat(推荐)、sar
- 进程内存分布:pmap
- CPU负载:uptime、top
- 系统调用追踪:strace(推荐)
- 网络吞吐量:iftop、nethogs、sar
- 网络延迟:ping
- CPU使用率:pidstat(推荐)、vmstat、mpstat、top、sar、time
- 上下文切换:pidstat(推荐)、vmstat、perf
对C++感兴趣可以看这里:我把相当多的C++文章都整理到了程序喵/cpp-learning上,想了解更多C++技术可以到程序喵/cpp-learning来看。


以下是作者介绍:

Copy/move elision: C++ 17 vs C++ 11
Copy elision 在C++11以前是省略copy constructor,但是C++11之后,更多地是指省略move constructor(只有copy constructor而没有move constructor的时候就是省略copy constructor)。C++ 17与11省略的方式还不一样,因为value categories有了调整。更多内容请看本文分析。
如果希望复习一下copy constructor和move constructor,可以阅读C++:Rule of five/zero 以及Rust:Rule of two 和什么是move?理解C++ Value categories和Rust的move
文章经过修改整理后,发于公众号 Copy/move elision: C++ 17 vs C++ 11
什么是copy elision?
Copy elision是指编译器为了优化,将不需要的copy/move 操作(含析构函数,为了行文简洁,本文忽略析构函数的省略)直接去掉了。要理解copy elision,让我们先看看函数是如何返回值的。比如下面的函数返回一个Verbose对象
Verbose createWithPrvalue()
{
return Verbose();
}
Verbose v = createWithPrvalue();
在没有优化发生的时候,编译器在返回createWithPrvalue()的时候,做了下面三件事
- 创建临时的Verbose对象,
- 将临时的Verbose对象复制到函数的返回值,
- 将返回值复制到变量v。
copy elision就是将第1和第2步的对象优化掉了,直接创建Verbose对象并绑定到变量v。这样只用创建一次对象。
下面让我们用可以实际编译和运行的例子来近距离观察copy elision。(推荐试着运行代码,更好地理解)
下面的代码包含了Verbose 类和create()函数。
#include <iostream>
class Verbose {
int i;
public:
Verbose() { std::cout << "Constructed\n"; }
Verbose(const Verbose&) { std::cout << "Copied\n"; }
Verbose(Verbose&&) {
std::cout << "Moved\n"; }
};
Verbose create() {
Verbose tv;
return tv;
}
int main() {
Verbose v = create();
return 0;
}
当没有copy elision的时候,也就是使用-fno-elide-constructors 编译flag的时候:
C++ 11编译代码并运行
g++ -std=c++11 -fno-elide-constructors main.cpp -o main
./main
输出是
Constructed
Moved
Moved
而如果用C++ 17编译代码和运行,输出是
Constructed
Moved
从输出,我们可以看到对象被创建后,又被move了(C++11 move两次,C++17move了一次,下文再分析为什么次数不一样)。如果不理解move,可以先阅读什么是move?理解C++ Value categories和Rust的move
让我们看看有copy elision的时候输出是什么。C++ 11和C++17这时候输出是一致的
Constructed
所以copy elision将move constructor的调用给省略了(没有move constructor的时候,省略copy constructor)。而在什么时候以及怎么省略的呢?
move constructor的省略
C++ 11
如果不发生copy elision,在C++ 11Verbose v = create()发生下面的5件事
- 未调用函数
create()前,选择一个空间v-space用来存储v。 - 准备进入函数
create()时,选择一个临时的空间temp-space来存储函数的返回值。 - 进入函数后,选择一个地址创建tv。
- 函数返回时,将tv 移动到temp-space。
- 赋值的时候,从temp-space 将tv 移动到v-space。
可以看到,发生了两次move(第四和第五步),所以输出了两个"moved"。我们可以从下面的汇编代码进行确定。(如果看不懂汇编并且想要看懂的话,请阅读如何阅读简单的汇编(持续更新))
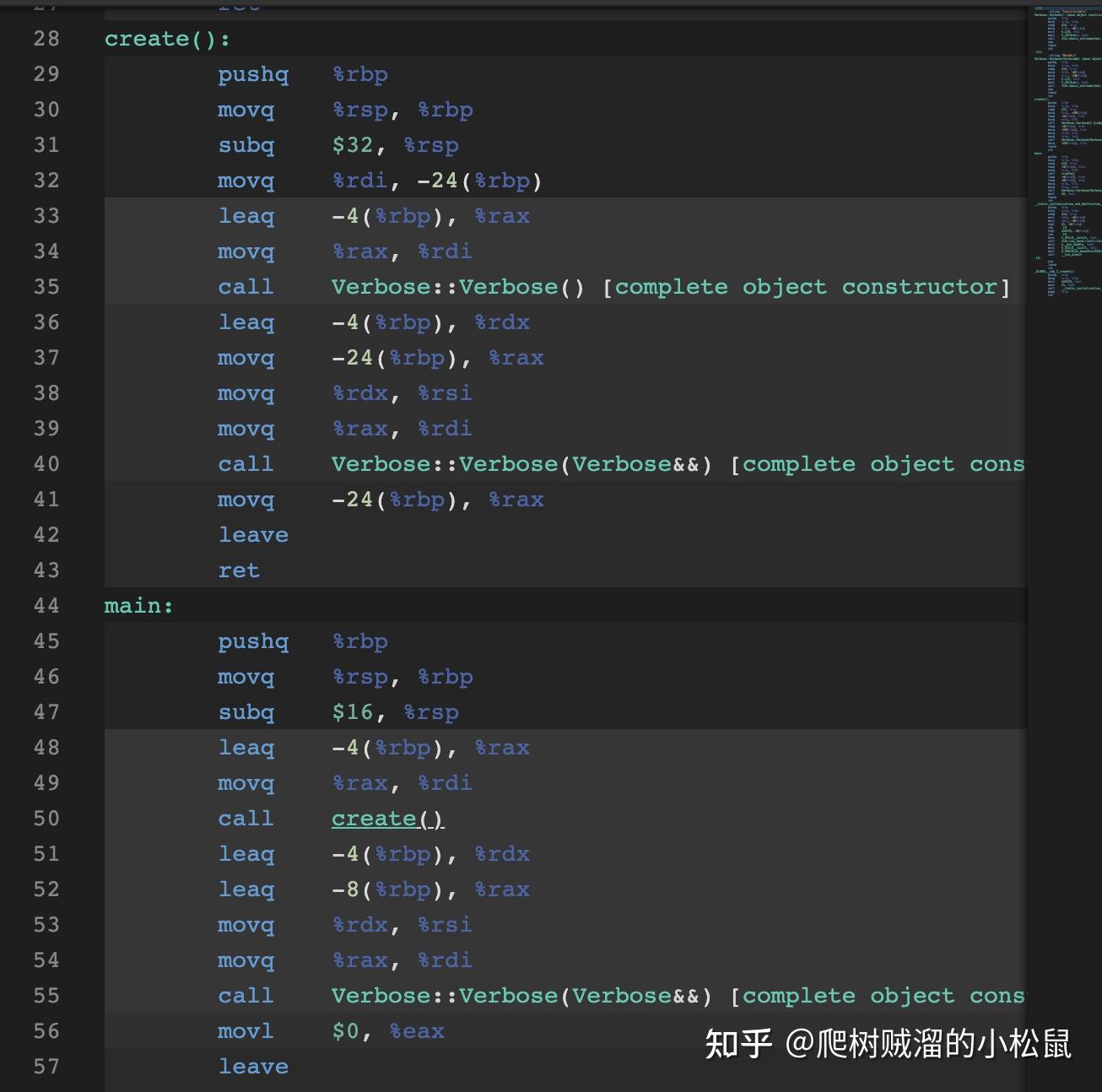
而当发生copy elison的时候,这两个moved都被省略了,因为上面的第三步创建tv,直接在v-space创建了,所以就不用发生第四步和第五步的move。请看下面的汇编,
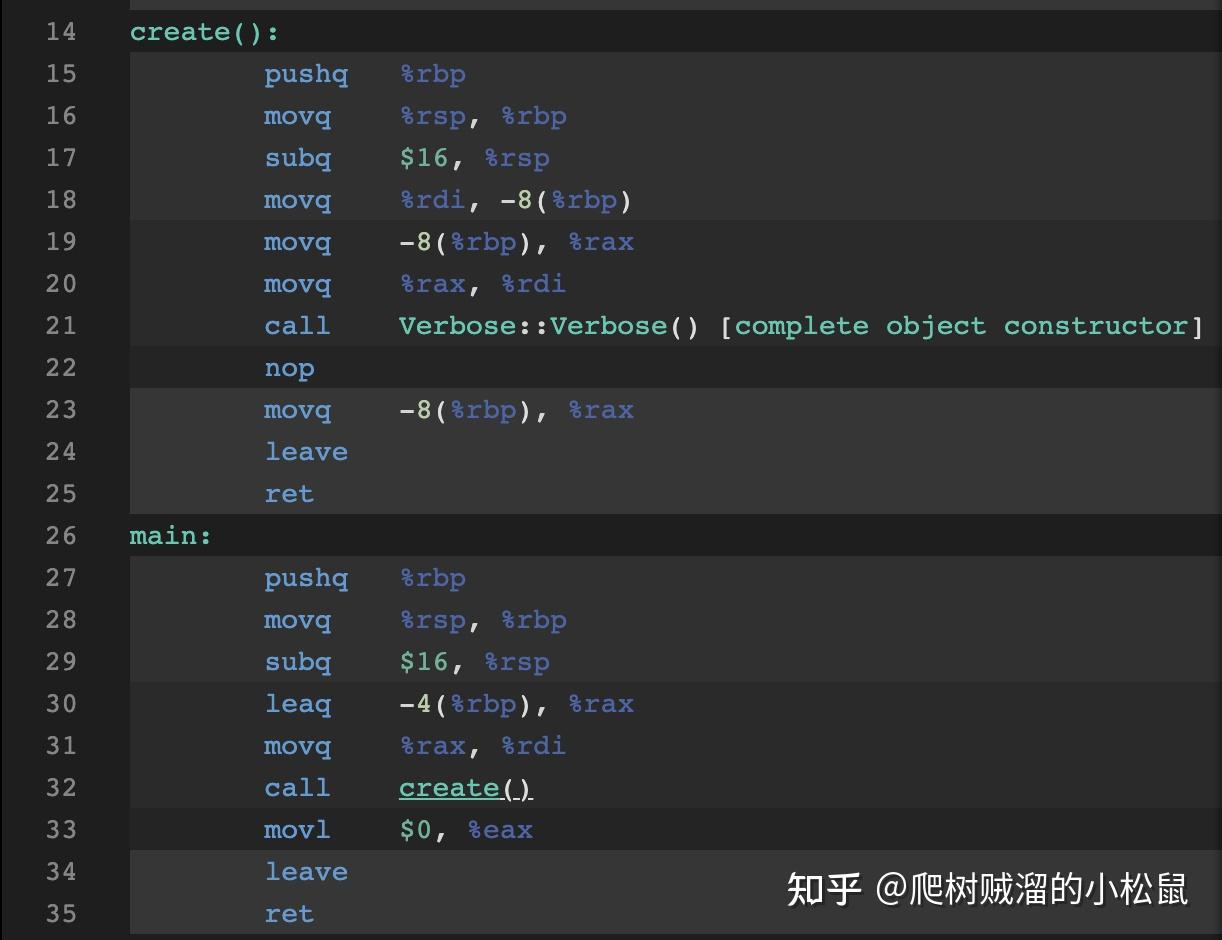
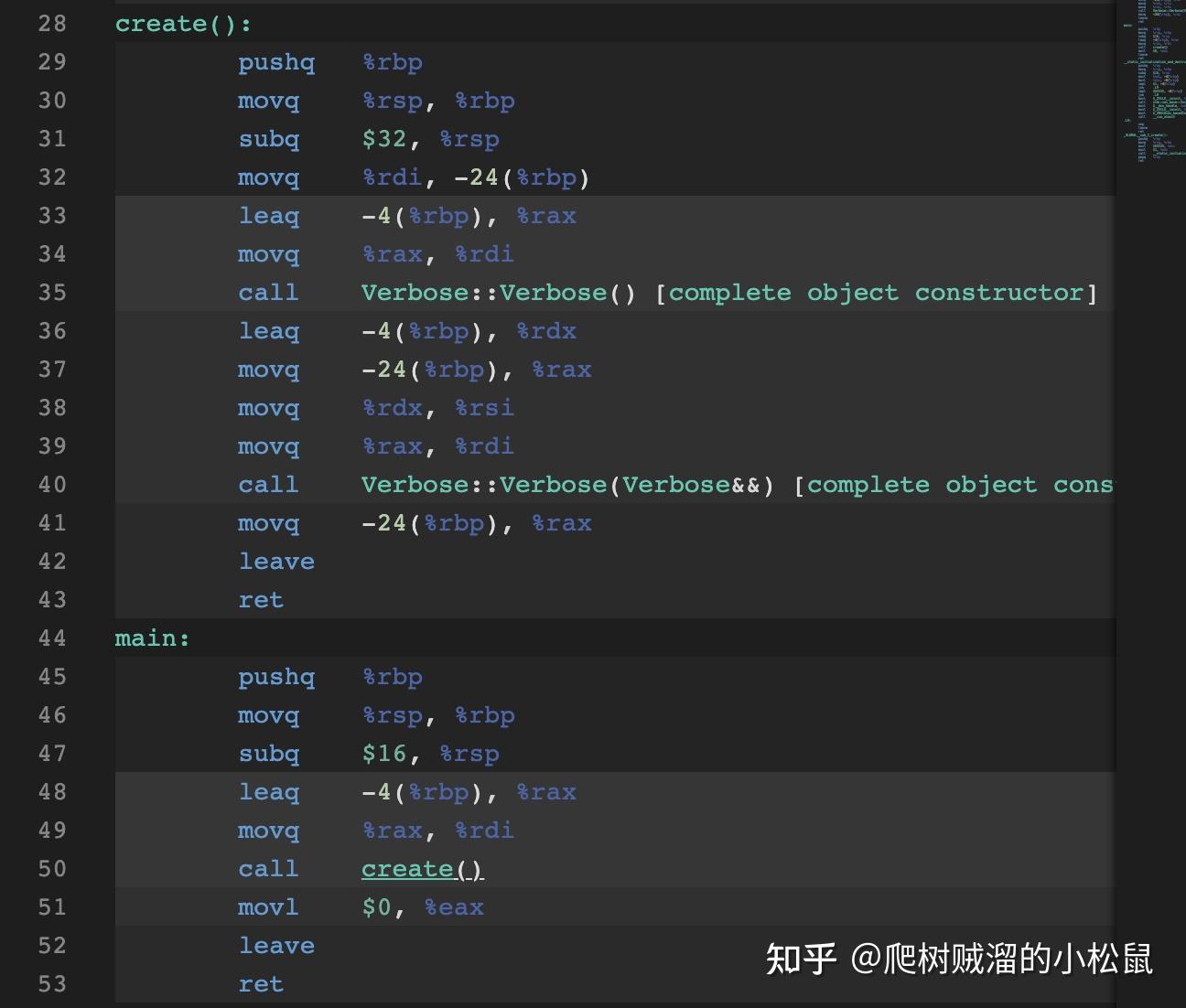
C++ 17
当没有copy elision的时候,为什么C++17 只被move了一次。因为C++17将temp-space等同于v-space,第五步不存在了。对应的汇编代码是
很神奇吧!C++ 17跟C++11的不同,源于C++17的value categories有了更容易理解和一致的定义——将prvalue定义为用于初始化对象的值。create()返回的是prvalue,而prvalue用来创建v的时候,是直接构造。所以没有了temp-space到v-space的move。更多关于value categories请看什么是move?理解C++ Value categories和Rust的move
RVO 和NRVO
请问下面的三个写法有什么区别,哪一个是推荐的写法,哪一个是不推荐的?
// 写法一
Verbose create() {
return Verbose();
}
//写法二
Verbose create() {
Verbose v;
return v;
}
//写法三
Verbose create() {
Verbose v;
return std::move(v);
}
RVO是返回值优化,就是将返回值的创建省略了。NRVO是函数内具有名字的局部变量充当返回值的时候,它的创建也被省略了。它们的省略结果都是在最终的变量里创建对象。
在C++没有move的时候,很多编译器实现就支持RVO(return value optimization)和NRVO(named return value optimization)。这两种优化用于在返回值的时候避免不必要的copy。在C++11以后,引入了move,move的存在与copy elision交织在一起。在这里直接给出答案,写法一是推荐的,写法二场景需要就推荐,而写法三是不推荐的。大家可以通过运行代码查看对应的输出从而得到答案。
C++17以后,RVO是保证会发生的,因为标准这么定义了。而NRVO并没有保证会发生,但是大部分编译器都会实现。所以在C++17里面,没有copy elision的时候只有一个moved,因为RVO也存在,而这个moved,是由于NRVO没有开启生成的。如果开启优化,那么一个moved也没有,因为NRVO把这个moved给优化掉了。当用prvalue创建对象的时候,直接会构造对象,而不用调用那几个构造函数。
所以C++17以后就不用再提RVO了,因为已经是语言标准,而不是优化了。
之前有人请教,函数调用者怎么知道是不是发生了copy elision,如果不知道发生了copy elision,那么怎么正确地调用函数?
实际上,函数调用者不需要知道是不是发生了copy elision,因为non-trivial 对象返回都是Caller直接传递存储对象的地址。区别是发生了copy elision的时候,直接在传递的地址构造了对象;而没有发生copy elision的时候,需要先创建对象,然后将对象move到temp-space,最后move到v-space。更多内容请看上面的讲解和汇编。
参考文献
Copy elision - cppreference.com
Interaction between Move Semantic and Copy Elision in C++
Wording for guaranteed copy elision through simplified value categories
极大提高你开发效率的C++ tricks(不定期更新)
作者:程序员阿德
链接:https://zhuanlan.zhihu.com/p/346465585
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
熟练使用 Python 进行开发,用惯了 Python 提供的各种现成库后,换到 C++有点难受,很多小工具需要自己编写,而且很多语法比较繁琐。
后来用习惯 C++ 后,发现原来 C++ 提供了这么多 tricks,可以大大提高你的开发效率,我特意总结了十个常用小技巧,不但提升你的工作效率,也能让你的代码更加简洁。
注:目前最流行的版本为C++11,所以只考虑该版本下的用法,如果有其他的,欢迎评论区补充。
1、对多个值取最值
你可能知道 C++标准库提供了获取最大值和最小值的方法:
int mi = std::min(x1, x2);
int ma = std::max(x1, x2);
但是如果想获取超过两个数的最值呢?
可以使用嵌套的方法,比如这样:
int mi = std::min(x1, std::min(x2, std::min(x3, x4)));
这样写有点麻烦,下面是更简单的方法:
int mi = std::min({x1, x2, x3, x4})
2、万能头文件
使用 C++ 进行开发时,每用到一个库函数,就需要在代码中 include 该库函数的头文件,比如 string, vector, fstream, thread, list, algorithm……
有时候光头文件就占了十多行,看起来比较冗长,这里有个万能头文件 bits/stdc++.h,它基本上包括所有的 C++ 标准库,所以在代码中只需要包含这一个头文件即可。
#include <bits/stdc++.h>
可以查看万能文件的源码: bits/stdc++.h header file
缺点还是有的,它会包含许多代码可能不需要的文件,这会增加编译时间,和程序文件的大小。
3、auto 关键字
使用 auto 关键字可以让编译器在编译时自动推导出变量的数据类型,而不需要你手动指定。
比如这篇文章
 程序员阿德:你的程序慢不慢?如何优雅地统计C++代码耗时117 赞同 · 11 评论 文章
程序员阿德:你的程序慢不慢?如何优雅地统计C++代码耗时117 赞同 · 11 评论 文章
我在介绍计时器和时钟时,里面涉及到的的数据类型名称都非常长,下面简单实现了一个计时器:
#include <iostream>
#include <chrono>
#include <thread>
int main() {
std::chrono::time_point<std::chrono::system_clock> start = std::chrono::system_clock::now();
{
std::this_thread::sleep_for(std::chrono::seconds(2));
}
std::chrono::time_point<std::chrono::system_clock> end = std::chrono::system_clock::now();
std::chrono::duration<double> elapsed = end - start;
std::cout << "Elapsed time: " << elapsed.count() << "s";
return 0;
}
start 和 end 变量的数据类型很复杂,下面是使用 auto 关键字的代码,看起来就简洁了很多。
#include <iostream>
#include <chrono>
#include <thread>
int main() {
auto start = std::chrono::system_clock::now();
{
std::this_thread::sleep_for(std::chrono::seconds(2));
}
auto end = std::chrono::system_clock::now();
auto elapsed = end - start;
std::cout << "Elapsed time: " << elapsed.count() << "s";
return 0;
}
还有使用容器的场景,比如 map<string, vector<pair<int, int>>> 之类的数据类型,使用 auto 就非常方便。
4、Lambda 表达式
C++11 引入了 Lambda 表达式,可以实现匿名函数,一种没有函数名的函数对象,并且它基于一些简洁的语法可以在各种其他作用域内捕获变量。
如果你需要在代码内部完成一些小的快速操作,没有必要为此编写一个单独的函数,就可以使用 Lambda,一个很常用的场景是将它用在排序函数中。
在使用 sort 函数时,想自定义排序规则,则需要编写一个比较器函数来实现该规则,再将该函数传入 sort 函数中。
比如根据数字的个位数进行排序:
#include <vector>
#include <algorithm>
bool cmp(int a, int b){
// 按个位数从大到小排序
return (a % 10) > (b % 10);
}
int main() {
std::vector<int> v;
v = {1, 53, 17, 25};
// sort
std::sort(v.begin(), v.end(), cmp);
}
// output: [17 25 53 1]
通过 Lambda 表达式,就不用显式编写 cmp 函数。
std::sort(v.begin(), v.end(), [](int a,int b){return (a % 10) > (b % 10);});
可能你还不太会使用 Lambda,基本形式如下:
[](argument1,argument2,.....){//code}
在 () 中传入参数,在 {} 中编写代码,[] 是一个捕获列表,可以指定外部作用域中,可以使用的局部变量:
[]— 捕获列表为空,表示在 lambda 表达式中不能使用任何外部作用域的局部变量,只能使用传进去的参数。[=]— 表示按照值传递的方法捕获父作用域的所有变量。[&]— 表示按照引用传递的方法捕获父作用域的所有变量。[this]— 在成员函数中,按照值传递的方法捕获 this 指针。[a, &b]— 不建议直接使用 [=] 或 [&] 捕获所有变量,可以按需显式捕获,就是在 [] 指定变量名,[a]表示值传递,[&b]表示引用传递。
5、用 emplace_back 代替 push_back
在 C++11 中,emplace_back 的用法功能与 push_back 类似,都是在向量的末尾添加元素。
但 emplace_back 比 push_back 更有效率,因为 push_back 会先创建一个临时变量(构造函数),然后将其拷贝到 vector 的末尾(拷贝构造函数)。但 emplace_back 就直接在 vector 的末尾构造值(构造函数),少调用了一次拷贝构造函数。
两者的用法相同:
#include <vector>
std::vector<int> v;
v.push_back(0);
v.emplace_back(1);
6、使用 tuple
对于两个不同类型的元素可以用:
std::pair<int, char> pi = std::make_pair(1, 'a');
std::cout << pi.first << " " << pi.second << std::endl;
如果有超过两个元素,且数据类型不同,可以使用 pair 的嵌套,使用时需要不断地调用 first 和 second。
std::pair<int, std::pair<char, std::string>> pi = std::make_pair(1, std::make_pair('a', "he"));
std::cout << pi.first << " " << pi.second.first << std::endl;
这种用法比较繁琐,也可以使用 tuple 进行简化,tuple 是各种数据类型的集合,相当于一个形式更简单的结构体。
#include <tuple>
std::tuple<int, char, std::string> tp = std::make_tuple(1, 'a', "he");
std::cout << std::get<0>(tp) << "," << std::get<1>(tp) << "," << std::get<2>(tp) << std::endl;
通过 std::get<id>(tp) 来获取 tp 中的每个值。
7、for 循环的简便写法
当遍历 vector 中每个元素时,我之前的写法:
std::vector<int> s = {8, 2, 3, 1};
for (std::vector<int>::iterator it = s.begin(); it != s.end(); ++it) {
std::cout << *it << ' ';
}
当时觉得这么写好复杂,就上网找简便一点的写法,果然被我找到了。
C++11 的 for 循环支持下面这种写法:
std::vector<int> v = {8, 2, 3, 1};
for (int i: v) {
std::cout << i << ' ';
}
其中 i 就是 vector 中的每个元素,还可以配合 auto 关键字,食用更佳。
8、不用 for 循环,计算一个数字的位数
#include <iostream>
#include <cmath>
int main() {
// cmath
int N=105050;
int n= std::floor(std::log10(N))+1;
std::cout << n;
return 0;
}
9、不用 for 循环,对数组进行深拷贝
使用 copy_n 函数可以从源容器复制指定个数的元素到目的容器中。
#include <algorithm>
int x[3]={1,2,3};
int y[3];
std::copy_n(x, 3, y);
copy_n 有三个参数:
- 第一个参数是指向第一个源元素的输入迭代器;
- 第二个参数是需要复制的元素的个数;
- 第三个参数是指向目的容器的第一个位置的迭代器。
10、all_of, any_of, none_of
在 Python 中,有 all() 和 any() 来判断列表中的元素是否都满足条件,或者至少一个元素满足条件。
C++ 也能实现类似的功能,就是使用 all_of,any_of,none_of。这里需要用到前面提到的 Lambda 表达式。
判断数组所有元素是否都为正(all_of):
#include <algorithm>
#include <iostream>
int main() {
int ar[6] = {1, 2, 3, 4, 5, -6};
std::all_of(ar, ar+6, [](int x){ return x>0; })?
std::cout << "All are positive elements" :
std::cout << "All are not positive elements";
return 0;
}
判断数组是否至少有一个元素为正(any_of):
std::any_of(ar, ar+6, [](int x) { return x>0; })?
std::cout << "At least one are positive elements" :
std::cout << "all are not positive elements";
判断是否没有元素为正(none_of):
std::none_of(ar, ar+6, [](int x) { return x>0; })?
std::cout << "all are not positive elements" :
std::cout << "At least one are positive elements";
继续更新
11、获取元祖多个值
在 Python 中,可以使用下面方法同时获取多个值:
arr = (1, 2.0, "3")
a, b, c = arr
现在 C++11 也可以实现这个功能了,用到了 std::tie:
#include <string>
#include <tuple>
#include <iostream>
int main() {
std::tuple<int, double, std::string> t0 = {1, 2.0, "3"};
int i = 0; double d = 0.; std::string s = "";
std::tie(i, d, s) = t0;
std::cout << i << " " << d << " " << s << std::endl;
return 0;
}
代码中定义了元祖 t0,通过 std::tie(i, d, s)= t0; 同时获取了元祖中的三个值。
有时候想只获取元祖中的部分值,则需要用到 std::ignore, 比如只获取前两个值:
std::tie(i, d, td::ignore) = t0;
std::tie 不但可用于 tuple,还能用于 pair。
12、数组去重
在 python 中对列表去重,有一个简单方法,就是将列表转换为集合 set,其实 C++ 也有类似的操作。
#include <set>
#include <vector>
int main()
{
std::vector<int> vec;
vec = {1, 2, 4, 5, 1, 6, 1, 2};
std::set<int> s(vec.begin(), vec.end());
vec.assign(s.begin(), s.end());
return 0;
}
13、拷贝任意文件
// 1
#include <fstream>
std::ifstream src(src_file_path, std::ios::binary);
std::ofstream dst(dst_file_path, std::ios::binary);
dst << src.rdbuf();
// 2 (C++17)
#include <filesystem>
std::fileystem::copy_file("source_filename", "dest_filename");
C++ 还有很多开发技巧,我这篇文章会不断保持更新,希望能够帮助到你,掌握这些技巧可以让你 C++ 开发更加游刃有余。C++ 学习其实没有难,我当时就是项目驱动学习,学会基本的语法后就到网上找项目做,在使用中学习。