![Linux中的Memory Compaction [一]](https://picx.zhimg.com/v2-0866738ee070d04e77f6ade81b9040de_720w.jpg?source=172ae18b)
Memory Compation: 内存归整
Linux使用的是虚拟地址,以提供进程地址空间的隔离。它还带来另一个好处,就是像vmalloc()这种分配,不用太在乎实际使用的物理内存的分布是否连续,因而也就弱化了物理内存才会面临的「内存碎片」问题。
但如果使用kmalloc(),且申请的是high order的内存大小(比如order为3,对应8个pages),则要求物理内存必须是连续的。在系统中空闲内存的总量(比如空闲10个pages)大于申请的内存大小,但没有连续的high order的物理内存时,我们可以通过migrate(迁移/移动)空闲的page frame,来聚合形成满足需求的连续的物理内存。
【实现原理】
来看下具体是如何操作的。假设现在有如下图所示的一段内存,其中有8个已使用的movable pages,8个空闲的free pages。
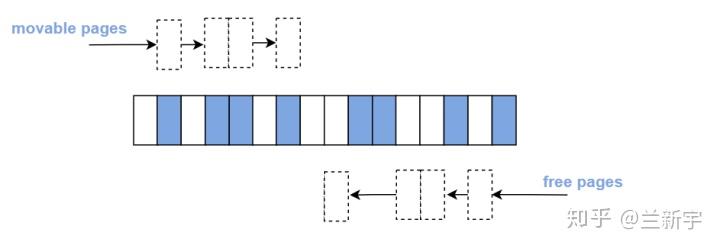
现在我们把左侧的4个movable pages和右侧的4个free pages交换位置,那么就会形成8个free pages全在左侧,8个movable pages全在右侧的情形。这时如果要分配order为3的内存就不是什么问题了。
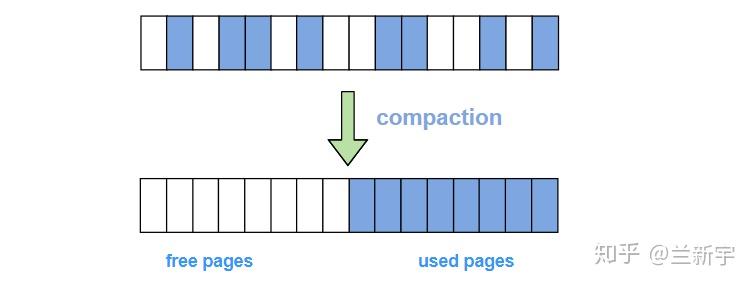
这样的一套机制在Linux中称为memory compaction, "compaction"中文直译过来的意思是「压实」,这里free pages就像是气泡一样,migration的过程相当于把这些气泡挤压了出来,把真正有内容的pages压实了。同时,这也可以看做是一个归纳整理的过程,因此"memory compaction"也被译做「内存规整」。
在此过程中,需要两个page scanners,一个是"migration scanner",用于从source端寻找可移动的页面,然后将这些页面从它们所在的LRU链表中isolate出来;另一个是"free scanner",用于从target端寻找空闲的页面,然后将这些页面从buddy分配器中isolate出来。

那一个page frame被migrate之后,使用这段内存的应用程序还怎么访问这个page的内容呢?这就又要归功于Linux中可以将物理实现与逻辑抽象相分离的虚拟内存机制了,程序访问的始终是虚拟地址,哪怕物理地址在migration的过程中被更改,只要修改下进程页表中对应的PTE项就可以了。虚拟地址保存不变,程序就"感觉"不到。
【使用限制】
由于要保持虚拟地址不变,像kernel space中线性映射的这部分物理内存就不能被migrate,因为线性映射中虚拟地址和物理地址之间是固定的偏移,migration导致的物理地址更改势必也造成虚拟地址的变化。也就是说,并非所有的page都是"可移动"的,这也是为什么buddy系统中划分了"migrate type"。
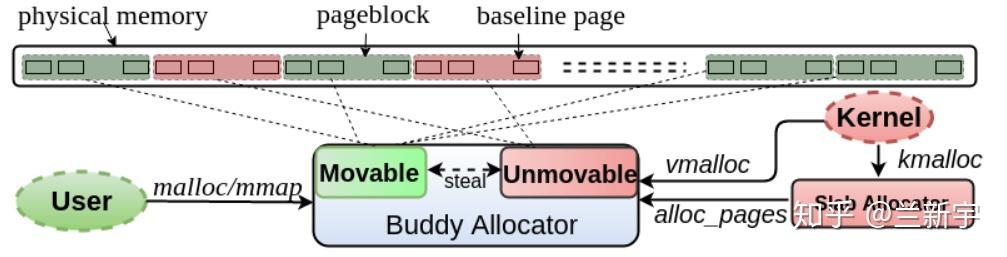
【何时启动】
在无法满足high order的内存分配时,可进行类似于"direct reclaim"的direct compaction,但它们都面临同样的问题:内存分配的过程被阻塞,增加分配等待的时间。
除了满足当前的high order的内存需求,内存的compaction机制还肩负着在buddy系统的基础上进一步减少内存碎片,为将来的high order的内存需求做好准备。那是不是应该稍微积极一点,像kswapd那样,在一定条件下被激活。
一种设想是干脆把内存compaction工作直接交给kswapd来完成,反正目的都是为了腾出更多可用的内存,在reclaim的时候把compact也做了。可是kswapd要做的事已经很多,这样会进一步增加kswapd的复杂性。
那就单独创建一个和kswapd类似的内核线程,专门负责"background compaction",这就是per-node的kcompated线程的雏形。
虽然compaction操作可以减少内存碎片,但其过程涉及到内存的拷贝和页表的重新建立,具有相当的开销,因而应该尽力避免,所以同kswapd一样,也是需要时才激活。kswapd是根据zone watermark的值被唤醒的,那kcompactd呢?可以像内存的writeback机制一样,每隔一段时间唤醒,具体的讨论请参考这个patch。
此外,提前准备好的high order内存,因而没有马上投入使用,可能在接下来的内存分配中又被split掉了,那之前的内存compaction岂不是白做了,所以引入background compaction后,是否需要对这些high order内存进行保护也是需要考虑的问题。
Linux中的Memory Compaction [二] - CMA
参考:
_原创文章,转载请注明出处。
内存带宽
mem stall
simpleperf stat \
-e cpu-cycles \
-e instructions \
-e raw-stall \
-e stalled-cycles-frontend \
-e stalled-cycles-backend \
-e raw-stall-frontend \
-e raw-stall-frontend-mem \
-e raw-stall-frontend-membound \
-e raw-stall-backend \
-e raw-stall-backend-mem \
-e raw-stall-backend-membound \
-e raw-stall-slot \
--duration 20 -a
或者
simpleperf record -a -e raw-stall --duration 10
simpleperf report | head -n 20
结果解读:
Performance counter statistics:
# count event_name # count / runtime
25,118,448,822 cpu-cycles # 0.156965 GHz
18,300,407,346 instructions # 1.372562 cycles per instruction
18,523,652,445 raw-stall # 115.738 M/sec
11,356,241,264 stalled-cycles-frontend # 70.953 M/sec
7,168,103,841 stalled-cycles-backend # 44.785 M/sec
11,356,444,789 raw-stall-frontend # 70.951 M/sec
0 raw-stall-frontend-mem # 0.000 /sec
5,002,356,389 raw-stall-frontend-membound # 31.253 M/sec
7,167,739,361 raw-stall-backend # 44.781 M/sec
1,378,331,738 raw-stall-backend-mem # 8.611 M/sec
1,378,274,808 raw-stall-backend-membound # 8.611 M/sec
77,979,205,840 raw-stall-slot # 487.187 M/sec
Total test time: 20.000292 seconds.
这些事件都是 CPU流水线停顿(stall) 的性能计数器,用于分析程序运行时因资源争用、依赖或缓存缺失导致的 性能瓶颈。它们源自 ARM Cortex 系列 CPU(如 A520)的 PMU(Performance Monitoring Unit)。
一、基本概念
现代 CPU 采用 流水线(pipeline) 结构,分为:
- Frontend(取指/解码):从内存取指令、解码。
- Backend(执行/写回):执行指令、访问数据、写结果。
当流水线因某种原因无法继续推进,就发生 stall(停顿)。
二、事件分类与含义
1. 通用/高层事件
| 事件 | 含义 | |——|——| | stalled-cycles-frontend | 前端停顿周期(如取不到指令) | | stalled-cycles-backend | 后端停顿周期(如等待数据) | | raw-stall | 任意槽位(slot)无操作发出(总停顿) |
这些是抽象事件,底层映射到具体 CPU 的原始事件。
2. 按停顿位置分
| 前缀 | 位置 | |——|——| | frontend | 停顿发生在 取指/解码阶段 | | backend | 停顿发生在 执行/数据访问阶段 | | slot | 从 发射槽(slot)视角 看是否发出操作 |
一个 cycle 可同时有 frontend 和 backend stall,但
raw-stall是整体指标。
3. 按停顿原因分(关键!)
| 原因 | 示例事件 | 说明 | |——|——–|——| | Cache/内存 | raw-stall-backend-l1d, -l1i, -mem, -membound | L1 数据/指令缓存缺失、内存延迟高 | | TLB | ...-tlb | 页表缓存缺失,需遍历页表 | | 数据依赖 | ...-ilock, -rename | 指令等待前一条结果(如 a = b + c; d = a + 1) | | 资源争用 | ...-busy, -vpu-hazard | 执行单元(如 VPU、ALU)忙 | | 控制流 | ...-flush, -flow | 分支预测失败、异常等导致流水线 flush |
三、事件关系(层级)
raw-stall
├── raw-stall-frontend
│ ├── raw-stall-frontend-l1i ← 指令缓存缺失
│ ├── raw-stall-frontend-tlb ← 指令 TLB 缺失
│ └── ...
└── raw-stall-backend
├── raw-stall-backend-l1d ← 数据缓存缺失
├── raw-stall-backend-mem ← 内存延迟
├── raw-stall-backend-ilock ← 数据依赖
└── ...
raw-stall= 所有停顿的总和。frontend/backend是互斥视角(但可能同时存在)。- 具体原因事件(如
-l1d)是backend的子集。
四、如何使用?
- 先看高层:
simpleperf record -e raw-stall,raw-stall-frontend,raw-stall-backend ...→ 判断瓶颈在前端(代码布局、分支)还是后端(数据访问、计算)。
- 再钻取原因:
- 若
backend高 → 看-l1d,-mem,-ilock。 - 若
frontend高 → 看-l1i,-tlb,-flush。
- 若
- 优化方向:
-mem/-l1d高 → 优化数据局部性、减少指针 chasing。-ilock高 → 减少长依赖链(如循环累加 → 分段并行)。-flush高 → 优化分支(减少 unpredictable if)。
五、内存相关的事件
| 事件 | 含义 |
|---|---|
raw-stall-backend-mem | 后端内存停顿:因等待内存(含 LLC/DRAM)响应 |
raw-stall-backend-membound | 内存带宽瓶颈导致的后端停顿 |
raw-stall-backend-l1d | L1 数据缓存缺失(需访问 L2 或内存) |
raw-stall-backend-tlb | 数据 TLB 缺失(需遍历页表) |
raw-stall-frontend-l1i | L1 指令缓存缺失(取指需访问内存) |
raw-stall-frontend-mem | 前端因内存延迟停顿(取指卡在内存) |
raw-stall-frontend-membound | 前端因内存带宽不足停顿 |
raw-stall-frontend-tlb | 指令 TLB 缺失 |